

Why do we think that one day we’ll broker usage of commodity clouds against each other for the lowest price per usage?
I’m in tune with the clouderatii. I’ve read the books equating the current transformation of IT into a continuous delivery pipeline as analogous to the recent past transformation of manufacturing into just in time. I’ve participated in the conferences. I’ve read the pundits blogs and tweets. I’ve listened to the podcasts.
I still have a question…
Is there really a precedent for this idea of brokering multiple commodity clouds, and deploying workloads anywhere you get the best price assuming everyone provides basically the same features?
I s it like an integrator sourcing the same component from multiple manufacturers? Is it like market brokering for the best price electricity from the grid? It’s like hedging fuel if you’re an airline?
s it like an integrator sourcing the same component from multiple manufacturers? Is it like market brokering for the best price electricity from the grid? It’s like hedging fuel if you’re an airline?
Maybe, but I’m not sure those are truly analogous. Is there an IT based precedent?
Is it like having a multi-vendor strategy for hardware, software, networking, or storage? (Does that really work anyway?)
I don’t think so.
I’ve had conversations of late about the reality (or not!) of multi-vendor cloud, and the need for vendor management of multiple cloud offerings. The idea seems to be that there will be a commoditization of cloud service providers, and through some market brokerage based solution, you’ll be able to deploy your next workload wherever you can get the best deal.
Keep in mind, I deal primarily with enterprise customers… not Silicon Valley customers.
There are still very few workloads that I see in the real world that fit this deploy-anywhere model. If they exist, these apps are very thin links in the value chain limited by network complexity and proximity to data. They typically exist to manage end-user interaction, pushing data to a central repository that doesn’t move. Maybe there are some embarrassingly parallel workloads that can be farmed out, but how big of a problem is data gravity? (the payload can’t be that big or the network costs eat you up) How often do you farm out work to the cloud? Is it so frequent that you need a brokerage tool, or will you simply negotiate for the best rate the next time you need it?
Multi-vendor IT management doesn’t come close to the dynamism suggested by such brokerage. In my experience individual management ecosystems are developed by each vendor to differentiate and make themselves “sticky” to the consumer. Some would say “lock-in,” but that’s not really fair if real value is gained.
Are all server vendors interchangeable such that you could have virtualization running on several vendor machines all clustered together? Only if you want a support nightmare. No one really does this at scale, do they? They may have a few racks of red servers and a few racks of blue, but they’re not really interchangeable due to the way they are managed and monitored.
Linux is a common example of this commoditization in action… Are all Linux OS’s the same? Can you just transition from RedHat to Ubuntu to SUSE on a whim? Do you run them all in production and arbitrage between them? You don’t, because even though they might be binary compatible Linux, each distribution is managed differently. They have different package management toolchains. They’ll all run KVM, true; but you’ll need to manage networking carefully. What about security and patching? Are they equally secure and on the same patch release cycle?
Shifts between vendors only really happen across multiple purchase cycles each with a 3-5 year term and with the cost of a lot of human effort.
Will the purchase cycle of cloud be 3-5 months of billing? Yes, this I could imagine. This would allow multiple cloud vendors to compete for business, and over 12 months or so a shop could transition from one cloud to another (depending on how frequently their workload instances are decommissioned and redeployed). And yet, network complexity and data gravity imply extreme difficulty in making the switch between clouds if app instances are clustered or must refer to common data sets; or if the data sets themselves must transition from one cloud to another (again with the network complexity and data gravity).
The only way to really engage in the brokerage model is to have very thin apps whose deployment does not rely on differentiated features of the cloud providers. You’ll have to create deployment artifacts that can run anywhere, and you’ll have to use network virtualization to allow them all to communicate back to the hub systems of record. Then there’s the proximity to the data to be processed. You’d better not be reliant on too much centralized data.
It’s too early to have all the answers, but I’m suggesting that the panacea of multi-cloud brokerage imagined by the pundits will never really materialize. If the past is any guide to the future, the differentiation of the various systems won’t allow easy commoditization. They’ll be managed differently, and it’ll be hard to move between them. Any toolset that provides a common framework for management will reduce usage to the least common denominator functionality. And nothing so far is really addressing network complexity or data gravity.
The issue is more complex than the pundits and the podcasts would have you believe. I don’t know the answers, do you think you do? I’d love to hear your opinions.
















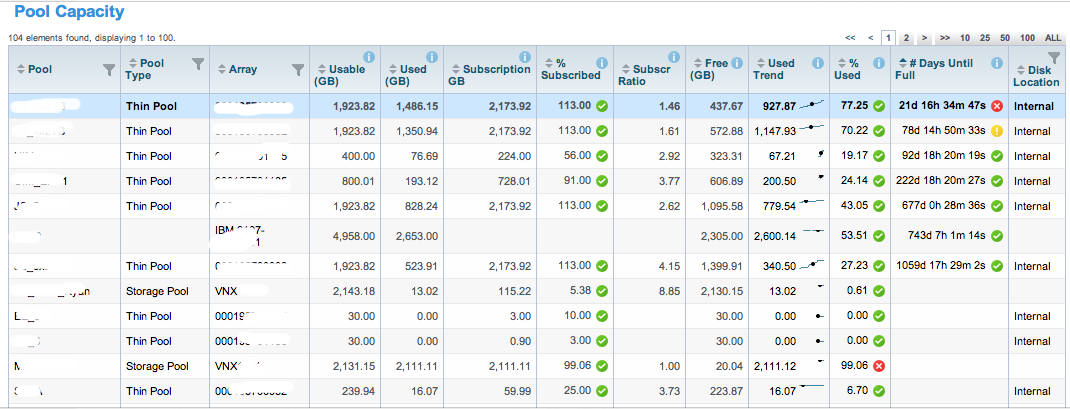

 Most vendor marketing has jumped onto the scale out bandwagon leaving implementations that also scale up indistinguishable from the rest. Properly conceived scale out architectures allow us to add additional discrete workloads to an existing system by adding nodes to the underlying infrastructure. The additional nodes accommodate processing required to support the additional separate workloads. This kind of share nothing design, allows us to stack a large quantity of discrete workloads together and manage the entire system is one entity, even though it can be very hard to balance workload across the nodes (silo’ed).
Most vendor marketing has jumped onto the scale out bandwagon leaving implementations that also scale up indistinguishable from the rest. Properly conceived scale out architectures allow us to add additional discrete workloads to an existing system by adding nodes to the underlying infrastructure. The additional nodes accommodate processing required to support the additional separate workloads. This kind of share nothing design, allows us to stack a large quantity of discrete workloads together and manage the entire system is one entity, even though it can be very hard to balance workload across the nodes (silo’ed). EMC scale out and up products such as VMAX Isilon, provide the cost benefits of a scale out model with the performance benefits of a scale up model. Purchasing only a few nodes initially, IT gains the cost benefit of starting small, and as workloads increase, additional nodes can be brought online, and data and workload is automatically redistributed across all nodes. This creates a share everything approach that supports the ability to scale up discrete applications and while also providing the ability to scale out stacking additional applications into the array along with the first. Software-based controls provide for multi-tenancy, tiering and performance optimization, workload priorities, and quality of service. This is as opposed to scale out architectures where rigid hardware defined partitions separate components of the solution.
EMC scale out and up products such as VMAX Isilon, provide the cost benefits of a scale out model with the performance benefits of a scale up model. Purchasing only a few nodes initially, IT gains the cost benefit of starting small, and as workloads increase, additional nodes can be brought online, and data and workload is automatically redistributed across all nodes. This creates a share everything approach that supports the ability to scale up discrete applications and while also providing the ability to scale out stacking additional applications into the array along with the first. Software-based controls provide for multi-tenancy, tiering and performance optimization, workload priorities, and quality of service. This is as opposed to scale out architectures where rigid hardware defined partitions separate components of the solution.